

Time series database
empowering Time-Driven Insights.
A high-performance,
open-source time series database
SiriDB emerged from a critical need: a database capable of storing time-series data with speed, scalability, and high availability. Recognizing this gap, Jeroen van der Heijden spearheaded the first version in 2015 and released it to the open-source community. In 2021, his involvement with Cesbit ignited a new chapter, where we committed to actively maintaining and advancing SiriDB's development.
SiriDB is the time-series database used by InfraSonar, among others. Ubiquti also uses SiriDB in their UISP platform.
Driven by a Vision
We envisioned SiriDB fulfilling specific, demanding requirements:
Seamless Scalability: Expansion without user disruption was paramount.
Unwavering Availability: Sensor data streams at high volumes, making downtime unacceptable. 99.99% availability became an unwavering goal.
Extensive Data Retention: Long-term storage of raw data empowered data-driven forecasting through machine learning and statistics.
Resource Optimization: In cloud environments, CPU and memory directly impact costs. Smart resource utilization translated to significant savings.
From Prototype to Powerhouse
The initial Python-based version prioritized rapid development, deliberately setting aside high availability and resource efficiency concerns. This enabled us to validate core functionalities through a Minimum Viable Product (MVP). However, to achieve our ambitious goals, we transitioned to C. Leveraging C routines within Python provided valuable insights, ultimately guiding us to rebuild the entire database in C for optimal performance and efficiency.
Result
SiriDB has a proven track record as a robust time-series database for solutions such as Oversight, InfraSonar and UISP.
The source code is also fully available as open source on GitHub.
Feaures
Highly available
SiriDB has a robust cluster mechanism that guarantees the availability of the data.
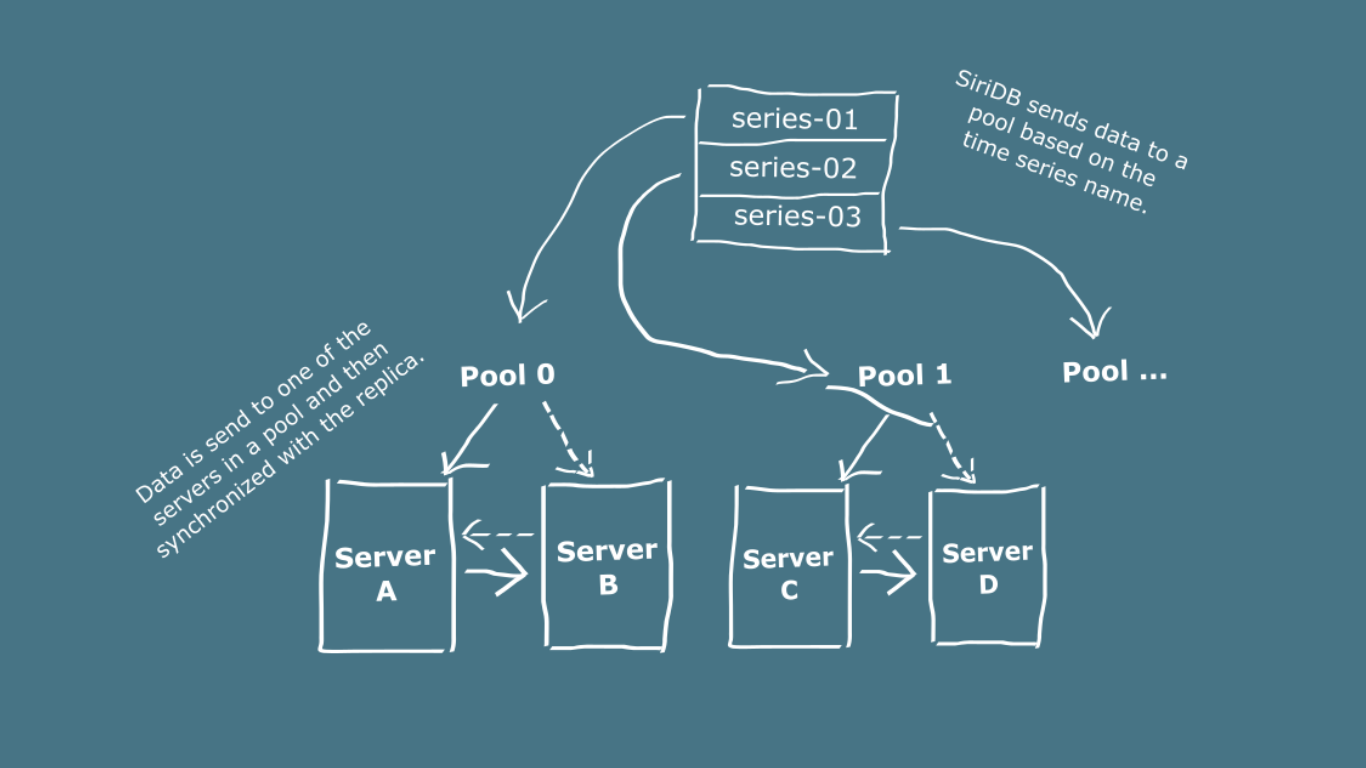
Scalable
A unique algorithm ensures that SiriDB data is optimally distributed across all available pools.
When a pool is added, the algorithm ensures that each pool passes a piece of their data to the new pool without a complete reshuffle of the data.

Designed for the cloud
SiriDB's unique algorithm stores its time-series data without using a global index.
A global index would be a limiting factor in SiriDB's scalability. We have therefore opted for a mathematical approach that makes a global index unnecessary. Every node has an index to be able to look up data very quickly.

Suitable for IoT
SiriDB is programmed in native C which makes it possible to compile SiriDB on almost any hardware platform.
During a demo at the IoT fair, we unlocked 10 years of Yahoo finance data on a cluster of 3 Raspberry Pi 3Bs.

